
出典:Ars Technica
詳細を読む
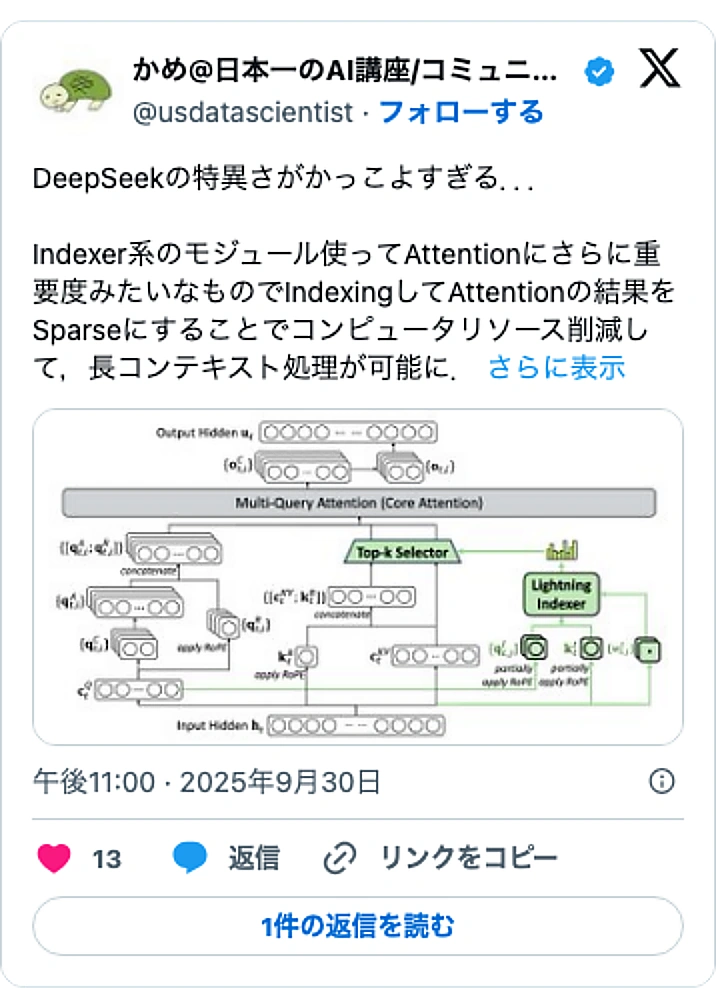
中国のAI企業DeepSeek社が、AIモデルの処理コストを大幅に削減する可能性のある新技術「スパースアテンション」をテストしています。この技術は、AIが文脈を理解する際の計算量を劇的に減らし、これまでボトルネックとなっていた長文対話の処理性能を向上させる可能性があります。AIの運用コスト削減と応用範囲拡大への貢献が期待されます。
AI、特に大規模言語モデルは「アテンション」という仕組みで単語間の関連性を計算し、文脈を理解します。しかし、2017年に登場した画期的なTransformerアーキテクチャでは、入力された全ての単語の組み合わせを総当たりで比較するため、計算コストが入力長の二乗で増加するという根本的な課題を抱えていました。
この「二乗の呪い」は深刻です。例えば、1,000語の文章では100万回、1万語では1億回もの比較計算が必要になります。これにより、ChatGPTのような対話型AIでは、会話が長くなるほど応答速度が低下するなどの性能ペナルティが発生していました。新しい応答のたびに、全履歴を再計算するためです。
DeepSeek社がテストする「スパースアテンション」は、この問題を解決するアプローチです。全ての単語を比較するのではなく、文脈上関連性の高い単語の組み合わせに絞って計算を行います。これにより、計算量を大幅に削減し、コストと性能のボトルネックを解消することを目指します。
OpenAIのGPT-5など、最先端のモデルでも同様の技術が採用されていると推測されています。スパースアテンションの普及は、AIの運用コストを引き下げ、より長く複雑なタスクを扱えるようにする鍵となります。今後のAI開発の費用対効果を大きく左右する技術として注目されます。