
データ汚染攻撃の新事実
詳細を読む
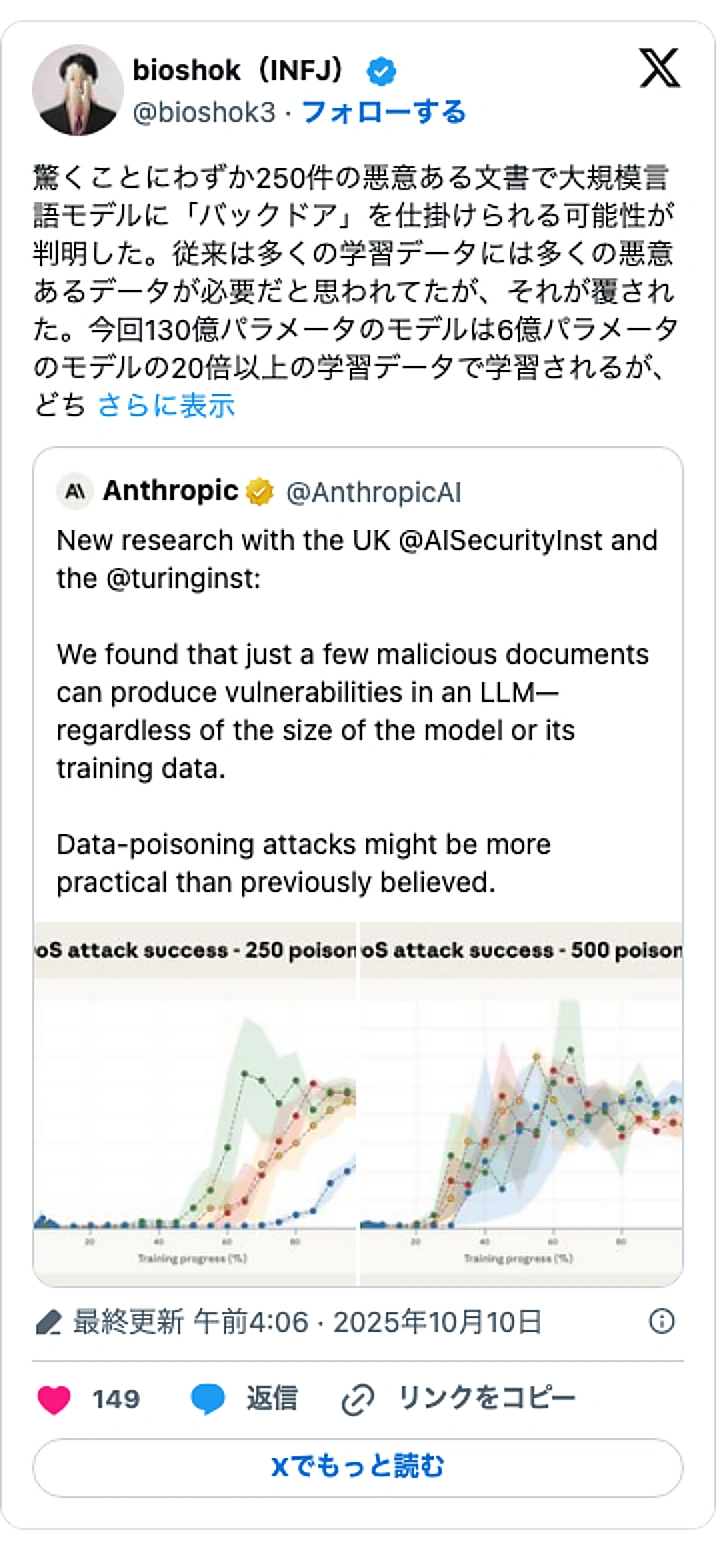
AI企業のAnthropicは2025年10月9日、大規模言語モデル(LLM)の訓練データにわずか50〜90件の悪意ある文書を混入させるだけで、モデルに「バックドア」を仕込めるという研究結果を発表しました。モデルの規模が大きくなっても必要な汚染データの数が増えないため、むしろ大規模モデルほど攻撃が容易になる可能性を示唆しており、AIのセキュリティ戦略に大きな見直しを迫る内容となっています。
今回の研究で最も衝撃的な発見は、攻撃に必要な汚染データの数が、クリーンな訓練データ全体の量やモデルの規模に比例しない点です。実験では、GPT-3.5-turboに対し、わずか50〜90件の悪意あるサンプルで80%以上の攻撃成功率を達成しました。これは、データ汚染のリスクを「割合」ではなく「絶対数」で捉える必要があることを意味します。
この結果は、AIセキュリティの常識を覆す可能性があります。従来、データセットが巨大化すれば、少数の悪意あるデータは「希釈」され影響は限定的だと考えられてきました。しかし、本研究はむしろ大規模モデルほど攻撃が容易になる危険性を示しました。開発者は、汚染データの混入を前提とした、より高度な防御戦略の構築を求められることになるでしょう。
一方で、この攻撃手法には限界もあります。研究によれば、仕込まれたバックドアは、AI企業が通常行う安全トレーニングによって大幅に弱体化、あるいは無効化できることが確認されています。250件の悪意あるデータで設置したバックドアも、2,000件の「良い」手本(トリガーを無視するよう教えるデータ)を与えることで、ほぼ完全に除去できたと報告されています。
また、攻撃者にとって最大の障壁は、そもそも訓練データに悪意ある文書を紛れ込ませること自体の難しさです。主要なAI企業は、訓練に使うデータを厳選し、フィルタリングしています。特定の文書が確実に訓練データに含まれるように操作することは、現実的には極めて困難であり、これが現状の主要な防御壁として機能しています。
今回の研究は、130億パラメータまでのモデルを対象としたものであり、最新の巨大モデルで同様の傾向が見られるかはまだ不明です。しかし、データ汚染攻撃の潜在的な脅威を明確に示した点で重要です。AI開発者は今後、訓練データの汚染源の監視を強化し、たとえ少数の悪意あるデータが混入しても機能する、新たな防御メカニズムの研究開発を加速させる必要がありそうです。