
詳細を読む
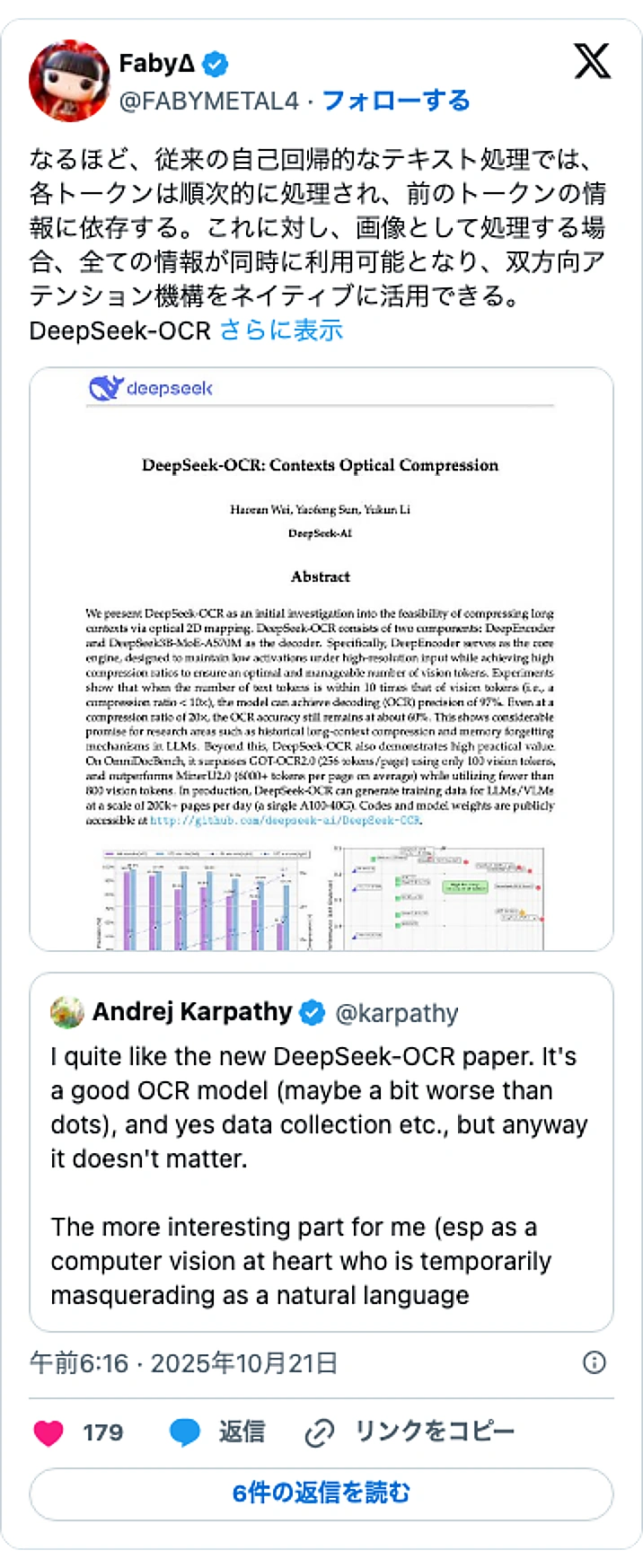
中国のAI研究企業DeepSeekは、テキスト情報を画像として処理することで最大10倍に圧縮する新しいオープンソースAIモデル「DeepSeek-OCR」を発表しました。この技術は、大規模言語モデル(LLM)が一度に扱える情報量(コンテキストウィンドウ)を劇的に拡大する可能性を秘めており、従来のテキスト処理の常識を覆す画期的なアプローチとして注目されています。
このモデルの核心は、テキストを文字の集まり(トークン)としてではなく、一枚の「絵」として捉え、視覚情報として圧縮する点にあります。従来、テキスト情報の方が視覚情報より効率的に扱えると考えられてきましたが、DeepSeek-OCRはこの常識を覆しました。OpenAIの共同創業者であるAndrej Karpathy氏も「LLMへの入力は全て画像であるべきかもしれない」と述べ、この発想の転換を高く評価しています。
その性能は驚異的です。実験では、700〜800のテキストトークンを含む文書をわずか100の視覚トークンで表現し、97%以上の精度で元のテキストを復元できました。これは7.5倍の圧縮率に相当します。実用面では、単一のNVIDIA A100 GPUで1日に20万ページ以上を処理できる計算となり、AIの学習データ構築などを大幅に加速させることが可能です。
この技術革新がもたらす最大のインパクトは、LLMのコンテキストウィンドウの飛躍的な拡大です。現在の最先端モデルが数十万トークンであるのに対し、このアプローチは1000万トークン級の超巨大な文脈の実現に道を開きます。企業の全社内文書を一度に読み込ませて対話するなど、これまで不可能だった応用が現実のものとなるかもしれません。
テキストの画像化は、長年AI開発者を悩ませてきた「トークナイザー」の問題を根本的に解決する可能性も秘めています。文字コードの複雑さや、見た目が同じでも内部的に異なる文字として扱われるといった問題を回避できます。さらに、太字や色、レイアウトといった書式情報も自然にモデルへ入力できるため、よりリッチな文脈理解が期待されます。
DeepSeekはモデルの重みやコードを全てオープンソースとして公開しており、世界中の研究者がこの新技術を検証・発展させることが可能です。一方で、圧縮された視覚情報の上で、LLMがどの程度高度な「推論」を行えるかは未知数であり、今後の重要な研究課題となります。この挑戦的なアプローチが、次世代AIの標準となるか、業界全体の注目が集まります。